
 Mindex
Mindex

1 min read
Building a Strong Data Foundation: Why Clean Data Ingestion Matters
Your company's data is one of its most valuable assets. In today’s digital landscape, leveraging data effectively is crucial for business growth,...

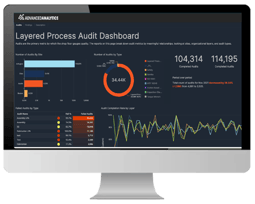
Transform your manufacturing data into real-time insight with Amazon QuickSight.

In today's big data era, effectively managing increasing volumes of data is crucial for organizations. Data ingestion is a vital step in the data pipeline, where data is gathered and imported from various sources into data management systems. However, this process is fraught with challenges. Many organizations encounter common pitfalls that can lead to low data quality and inaccurate insights. To sidestep these nightmares, it’s essential to understand these pitfalls and explore strategies for enhancing data quality control. In this blog post, we'll delve into the challenges of data ingestion and offer practical tips to overcome them.
Understanding data sources is a fundamental part of the data ingestion process, providing the necessary context and framework for how the data will be collected, processed, and analyzed. This comprehension goes beyond just knowing the origin of the data; it's about understanding the nature of the data, its format, its quality, and its potential impact on your overall analytics goals.
Are you dealing with structured data from an SQL database, semi-structured data from JSON or XML files, or unstructured data from social media feeds or text documents? How reliable is your data source? How often is it updated, and how quickly do you need to process it? Understanding the answers to these questions is crucial in designing an effective data ingestion pipeline. This not only helps in selecting the appropriate ingestion tools and methodologies for extraction but also influences how the data will be cleaned, transformed, and stored downstream.
Hence, understanding your data sources is crucial for the success of your data-driven projects, as it directly impacts your overall data strategy.
2. Ensuring Robust Data Validation and Cleansing
In the cloud-based data ecosystem, data validation and cleansing stand as integral parts of the data management process. As organizations increasingly leverage cloud platforms for data storage and analysis, the importance of maintaining high-quality data has become paramount. Data validation is the process of ensuring that incoming data adheres to predefined formats, standards, and business rules, while data cleansing refers to the identification and correction (or removal) of errors or inconsistencies in datasets. This could range from filling in missing values, rectifying format inconsistencies, or purging duplicate or irrelevant entries. The goal is to improve the accuracy, completeness, consistency, and reliability of the data, thereby enhancing its overall usability.
When implemented effectively, data validation and cleansing procedures in the cloud can significantly boost the accuracy of analytics and machine learning models, leading to more data-driven decision making and optimal business outcomes. The choice of validation and cleansing techniques should be tailored to your specific data requirements, always keeping in mind the nature of the data and the intended use. Furthermore, the automation of these processes can be a key enabler of scalability and efficiency in large-scale cloud-based data systems.
Scaling your data effectively is crucial to avoid performance bottlenecks and slow data processing as your data volume increases. So, be proactive and plan ahead for the future—keep a keen eye on your system's performance and be prepared for that data explosion! You can rely on cloud giants like AWS or Microsoft Azure, which have automatic scaling capabilities, to effortlessly handle increasing data loads. We highly recommend teaming up with a top-notch cloud partner like us at Mindex, who can guide you in the right direction.
Data security must be a top priority throughout the data ingestion process into the cloud. It is important to have strong security measures, such as encryption and access control, in place to protect sensitive data from unauthorized access. It is also crucial to be aware of compliance requirements like GDPR or HIPAA and strictly adhere to them. By implementing encryption, access controls, and complying with data protection regulations, businesses can avoid costly mistakes and protect themselves from potential consequences.
By implementing these safeguards, you can enhance the resilience of your data ecosystem and avoid costly mistakes.
In the world of data management, maintaining proper data governance and documentation is an absolute must. It forms the backbone of data quality control, and without it, you risk costly mistakes.
Don't worry; our aim isn't to intimidate you with potential mistakes, but rather, to empower you with knowledge! So, if you have any questions or need expert advice, reach out to our cloud experts today. You can count on us!



Xerox wanted to improve how users search and interact with large volumes of documents across its platform. As the platform evolved, managing and...

For Ironhorse Funding, delivering exceptional service to their customers is a top priority. Their leadership understands that great customer...
1 min read
Your company's data is one of its most valuable assets. In today’s digital landscape, leveraging data effectively is crucial for business growth,...

1 min read
ROCHESTER, NY – October 30, 2024 – Mindex, a leading provider of enterprise software development and cloud services, announced today that it has...

1 min read
With the rise of AI and generative AI technologies, businesses now have incredible opportunities to harness and analyze massive...