 Mindex
Mindex
1 min read
Unlocking the Power of Amazon Q: 🎬 Lights, Camera, Action!
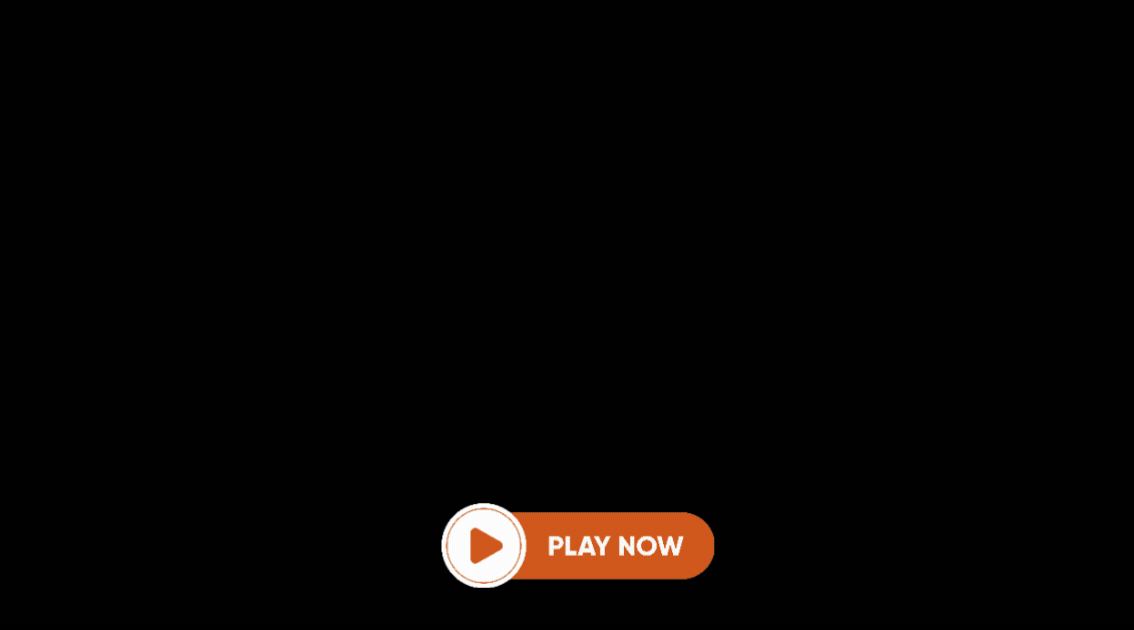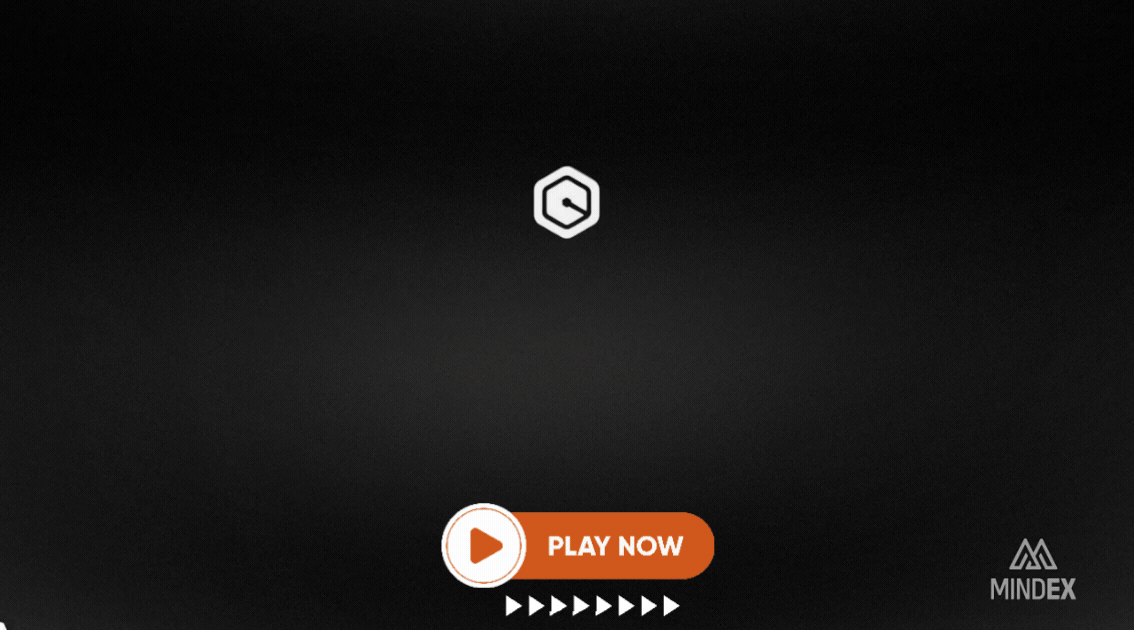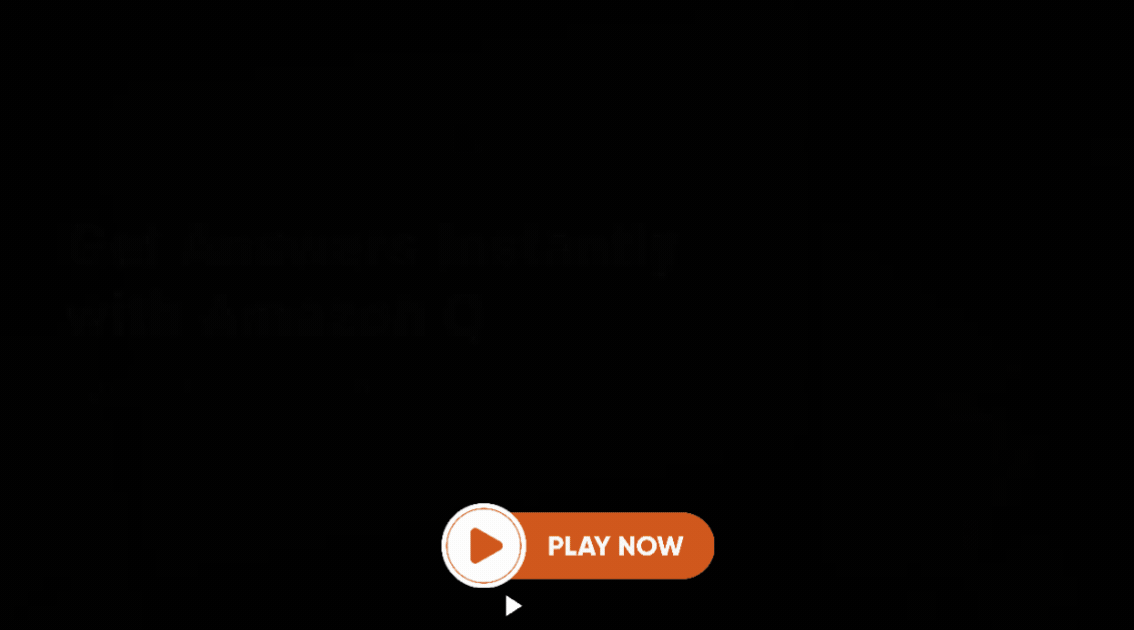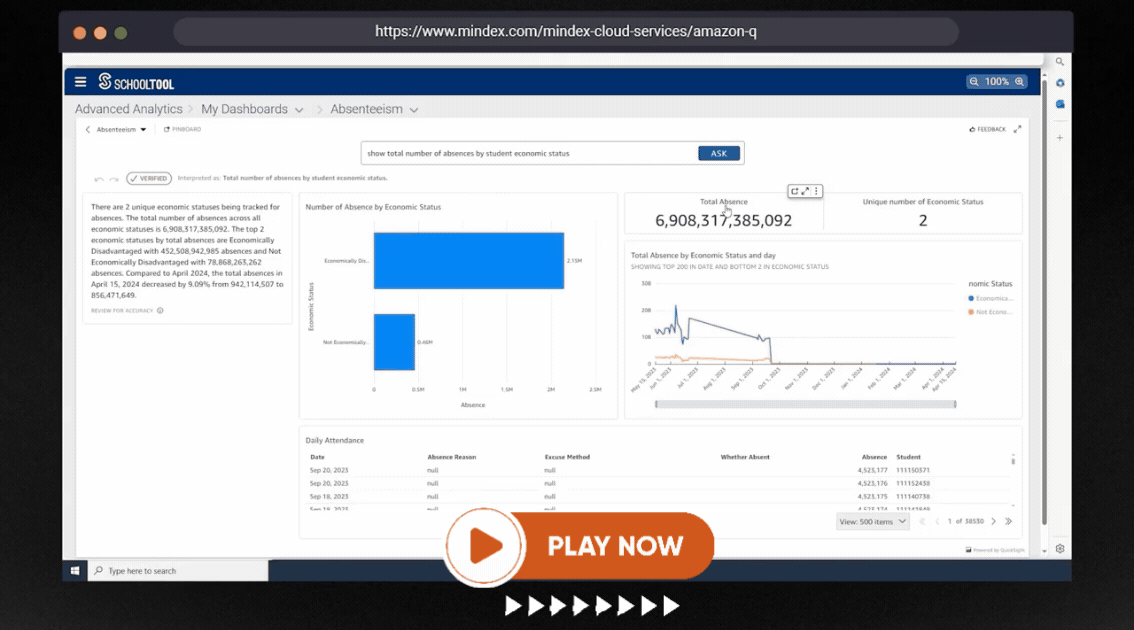
Are you curious about the buzz surrounding Amazon Q? If you've been following AWS or our updates on social media, you may have heard about it. If...




We live in a world where big data is becoming an integral part of decision-making processes, but managing a data lake is no small task. How can your organization ensure that it is properly governed to produce reliable insights?
A data lake contains a wide range of raw and unstructured datasets collected from multiple sources. In order for insights gained from this information to be trusted, there must be an effective governance process in place. This means that steps should be taken to guarantee the data's security, privacy, and accuracy.
Even though implementing sound data governance is critical for maintaining data integrity, it can be challenging. Here are five key challenges you must consider when creating and managing an effective data lake governance strategy.
What security measures should be in place for a data lake? Security protocols must be established from the outset. Data stored in a data lake can be vulnerable if proper systems for storing and accessing information aren’t created. At Mindex, we adhere to strict privacy and security regulations as an AWS cloud service provider, particularly in industries like healthcare and financial services. Our experience with rigorous New York State encryption requirements for our product, SchoolTool, a student management system, emphasizes the importance of strong security protocols.
How can organizations control access to their data lake? As data access expands, companies must implement access controls to ensure that only authorized personnel can view or edit specific data segments. This protects sensitive strategic and intellectual property from unauthorized access and misuse. Access controls also help organizations comply with regulatory requirements such as GDPR and HIPAA (Health Insurance Portability and Accountability Act).
Why is a classification system vital for data management? If you don't categorize a disparate set of structured and unstructured data sources uniformly upfront, you'll waste time manually matching all the fields when you query them during analysis. As a result of inconsistent record formats or variability in business definitions across different files, teams often face significant delays when interpreting datasets, making the ingestion of content for predictive analysis more difficult for analysts or machine learning algorithms. Sounds like a headache, right?
How can organizations maintain data quality and accuracy? Organizations may need to develop new habits for quality assurance regarding their data. We know it can be a burden, but we have seen the negative consequences time and again. In order to ensure quality assurance and trust in their systems' accuracy, companies must track and monitor data collection and cleansing processes. This entails reviewing a wide range of processes, such as capturing and cleansing data. By actively monitoring these processes, teams can gain confidence in their solutions and continuously optimize them to meet their expectations.
Why is traceability important for data management? Without robust data management systems and processes in place, organizations struggle to keep track of the source of information—which is important to ensure that data remains accurate, consistent, and easy to locate if it has been modified (such as changes to the name, format, or contents of a file) or moved over time.
Similar to supply chain management and the idea of tracking the origin of a product to ensure it is manufactured and distributed in compliance with regulations (or that the product meets quality and safety standards), maintaining traceability back to the original name is an important process in many different fields, as it helps to ensure that data is properly managed, and that its origins can be easily traced for reference or regulatory purposes.
At Mindex, we understand that data lake governance is a daunting task, so we have developed a data lakehouse approach that simplifies it. We can work with you to develop a governance plan that allows you to spend more time harnessing the power of your data rather than dealing with all these governance challenges.




Xerox wanted to improve how users search and interact with large volumes of documents across its platform. As the platform evolved, managing and...
1 min read
Are you curious about the buzz surrounding Amazon Q? If you've been following AWS or our updates on social media, you may have heard about it. If...

1 min read
Hello, I'm Caleb Kellicutt, a Software Engineer here at Mindex. I had the privilege of working closely with our client's software product, Nodeware®,...

1 min read
Each year, the Rochester Business Journal publishes its Book of Lists, recognizing leading organizations across a wide range of industries based on...