

.png?width=340&height=60&name=8cda0b58-762f-4aaf-a665-2c382dfa7eae%20(2).png)
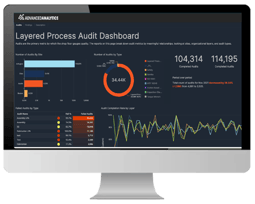
Data Ingestion
The First Step in Your Data Journey

Step 2
Data Storage

Step 3
Analytics
Engage our cloud data team for a Complimentary Data Architecture Review led by a Certified AWS Data Architect.
In this one-hour session, we'll review your data pipeline's key pillars: Data Ingestion, Storage, and Analytics (AI/ML, Business Intelligence). Our goal is to identify challenges, opportunities, and establish a long-term data strategy, outlining next steps to enhance your data, analytics, and AI journey.
