

- BIG DATA Case Study -

Accelerating Diagnostic Machine Performance
Real-Time Insights and Predictive Maintenance
Global Diagnostic Solutions Company
Our client is a global leader in diagnostic solutions that manufactures and sells medical diagnostic equipment to hospitals, hospital networks, blood banks and labs around the world to ensure test results are fast, accurate and reliable
Opportunity
A more efficient ETL pipeline solution was required by this diagnostic company to reduce costs and improve performance. Previously, their .NET was running on Microsoft Server instances for computing and Microsoft SQL Server Enterprise for data storage, both hosted in on-premise data centers. Our client came to Mindex seeking a more efficient, cost-effective solution, leading us to build a cloud-native application.
Solution
Mindex technical experts conducted a “deep dive” into the diagnostic company’s data to gain an expansive understanding of the functionality. Our solution consisted of replatforming their on-premise servers and databases to an AWS serverless stack in order to reduce Total Cost of Ownership (TCO) and accelerate machine test results.

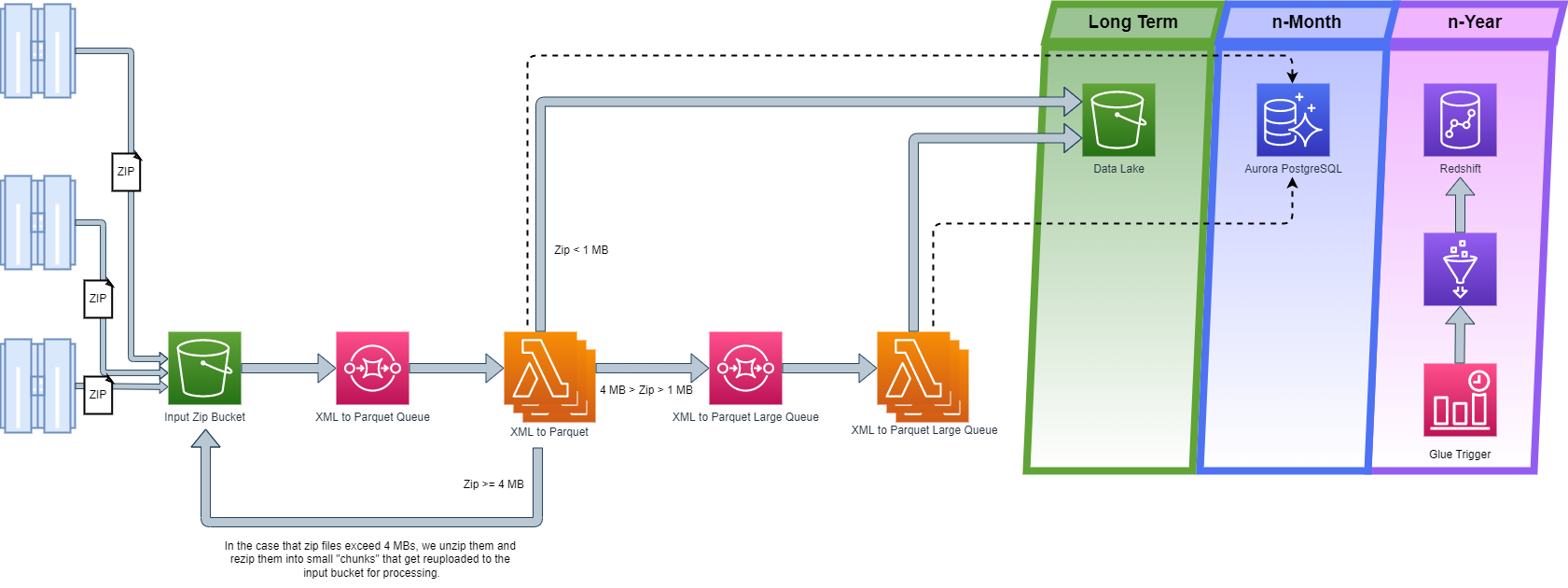
S3 Data Lake Formation
The Mindex cloud team recommended our client to replace their raw data logging Microsoft SQL server database with an Amazon S3 data lake. This allows them to store all their 3 TB raw logs at an infinite scale for a fraction of the cost.
Here's how we went about it:
-
IoT agents send zip files containing their machine's log data to Amazon S3.
-
Upon arrival to S3, an S3 event notification puts a message, containing the S3 file name and location, on an SQS queue.
-
AWS Lambda polls the SQS queue and receives the message as an event. After retrieving the new zip file from S3, Lambda ingests the data, extracts the raw XML files from within the zip file, and parses them. The parsed information is then converted to Parquet and stored in an S3 Bucket, which serves as the data lake.
-
The solution was built to scale infinitely, currently there are 33 zip files landing in S3 every minute, with an average of 90 xml files per zip file.
Our client is now able to analyze more machine data in less time, allowing them proactively to maintain and fix their equipment.

Real-Time and Analytical Reporting
Our cloud team selected AWS Aurora for real-time reporting and custom application logging due to its Online Transactional Processing (OLTP) capabilities and its ability to handle high-throughput queries.
We followed the following steps:
-
AWS Lambda functions are used to load the parsed and transformed machine and logging data into Aurora in real-time.
-
We recommended Amazon Redshift for business intelligence (BI) and analytical reporting due to its Online Analytical Processing (OLAP) workload capabilities. Our client uses AWS Redshift primarily for predictive analytics, enabling it to detect and maintain machines that are about to fail.
-
We implemented AWS Glue to read parquet files from the S3 data lake and load them into AWS Redshift using Glue dynamic frames on a nightly cadence.
Successes
The business impact of this project is transformational.

Operational Costs Reduced
Decommissioning SQL servers will reduce our client’s operating expenses and licensing costs over time.

View Test Results in Real-Time
As a result of this project, we developed a new, highly useful application to allow patients to view their test results in real time.

Reduction of Unplanned Machine Downtime
Machine data can be analyzed to predict maintenance needs. Avoids sending employees across the country for unplanned machine maintenance, saving time and resources.

Reduced Deployment Time & Effort
In the legacy system, deployments were done manually, creating the possibility of human error. In the AWS replatformed system, all AWS infrastructure and application code are built and deployed automatically via CI/CD pipelines.
Are you ready to embark on the cloud journey?
Apply for our complimentary cloud migration assessment to see what opportunities may exist for YOU!
